
Nvidia CEO のジェンスン・フアン氏は、発表だらけの基調講演で同社のグラフィックス テクノロジー カンファレンス (GTC) を開始しました。主要な公開内容には、Grace と名付けられた Nvidia 史上初のディスクリート CPU と、2022 年後半に登場予定の次世代 Hopper アーキテクチャが含まれます。

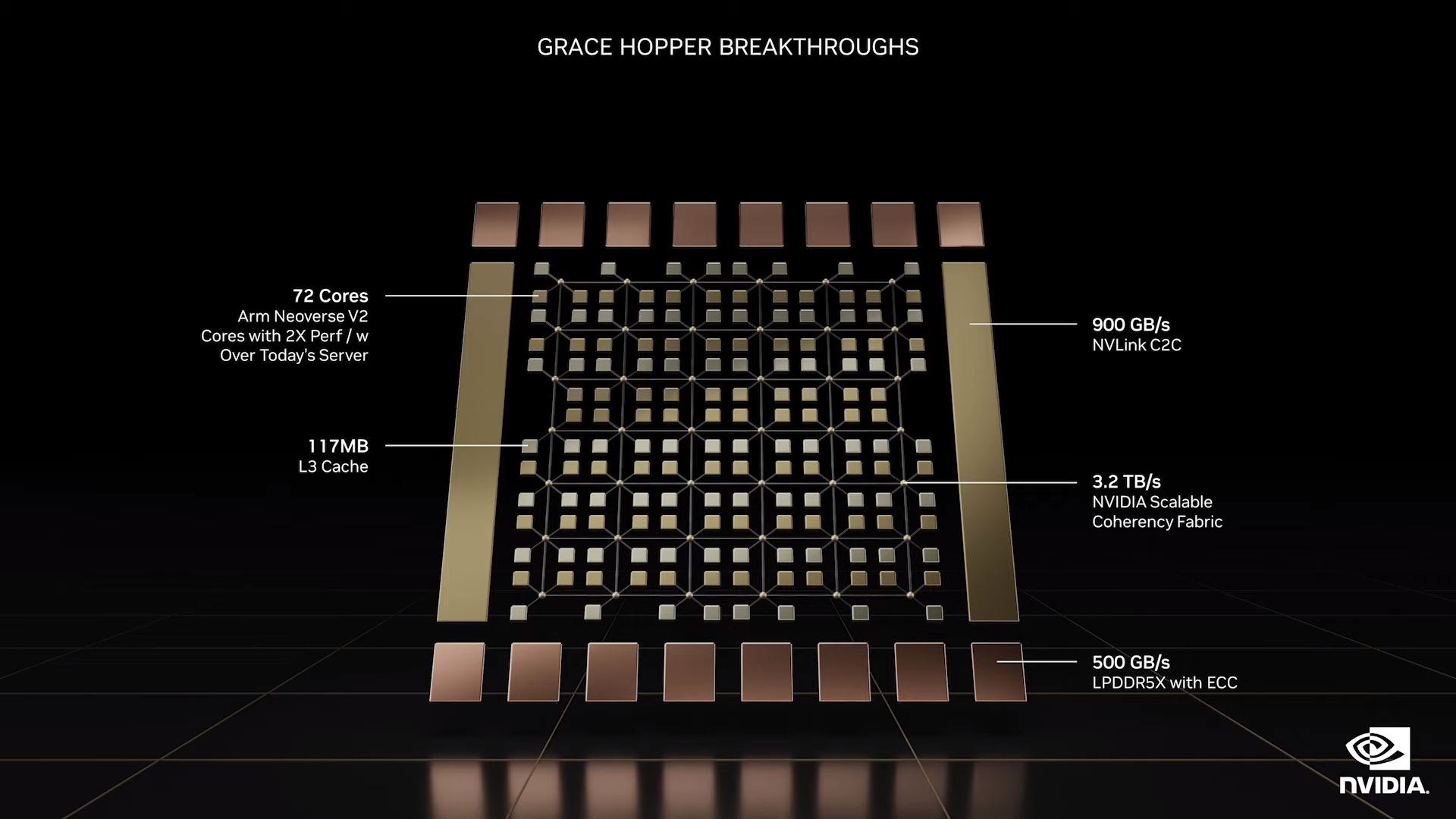
Grace CPU スーパーチップは、Nvidia 史上初のディスクリート CPU ですが、 次のゲーム PC の中心となるわけではありません。 Nvidia は を発表しましたが、Nvidia が呼ぶこのスーパーチップは新しいものです。これは、 Apple の M1 Ultra に似た 2 つの Grace CPU を組み合わせており、Nvidia の NVLink テクノロジーを通じて接続されています。

ただし、M1 Ultra とは異なり、Grace Superchip は一般的なパフォーマンスを目的として構築されていません。 144 コア GPU は、AI、データ サイエンス、およびメモリ要件の高いアプリケーション向けに構築されています。 Nvidiaが 400億ドルでの同社買収提案を断念した にもかかわらず、CPUは依然としてARMコアを使用している。
Grace Superchip に加えて、Nvidia は次世代の Hopper アーキテクチャを披露しました。推測によると、これは RTX 4080 を駆動するアーキテクチャではありません。代わりに、Nvidia のデータセンター アクセラレータ用に構築されています。 Nvidia は、 を置き換える H100 GPU のアーキテクチャをデビューさせます。

Nvidia は H100 を「世界で最も先進的なチップ」と呼んでいます。チップメーカー TSMC の N4 製造プロセスを使用して構築されており、800 億個という驚異的なトランジスタが詰め込まれています。それだけでは十分ではなかったかのように、PCIe 5.0 と HBM3 メモリをサポートする最初の GPU でもあります。 Nvidia は、わずか 20 個の H100 GPU で「全世界のインターネット トラフィックに相当する量を維持できる」と述べており、PCIe 5.0 と HBM3 の威力を示しています。
顧客は、8 つの H100 GPU と 640 GB の HBM3 メモリを組み合わせた Nvidia の第 4 世代 DGX サーバーを通じて GPU にアクセスできるようになります。 Nvidia によると、これらのマシンは 32 ペタフロップスの AI パフォーマンスを提供し、これは前世代の A100 の 6 倍です。
DGX が十分な電力を提供できない場合、Nvidia は DGX H100 SuperPod も提供しています。これは、Nvidia が レンタルしたことに基づいて構築されており、大規模なデータセンターの予算がない人でも AI の力を利用できるようになります。このマシンは 32 台の DGX H100 システムを組み合わせて、20 TB の巨大な HBM3 メモリと 1 exoFLOP の AI パフォーマンスを実現します。

Nvidia は、合計 4,608 個の H100 GPU に相当する 18 個の DGX H100 SuperPod を含む、独自の EOS スーパーコンピューターを備えた新しいアーキテクチャをデビューさせています。このシステムを実現するのは Nvidia の第 4 世代 NVLink であり、GPU の大規模なクラスター間に高帯域幅の相互接続を提供します。
GPU の数が増加するにつれて、Nvidia は、前世代の A100 がフラットラインになることを示しました。同社によれば、Hopper と第 4 世代 NVLink にはそのような問題はありません。 GPU の数が数千にスケールアップされるため、H100 ベースのシステムは A100 ベースのシステムよりも最大 9 倍高速な AI トレーニングを提供できると Nvidia は述べています。
Nvidia によれば、この次世代アーキテクチャは「革新的なパフォーマンス上の利点」を提供します。 AI とハイパフォーマンス コンピューティングの世界にとってはエキサイティングなことでありますが、私たちは依然として、今年後半に発売されると噂されている Nvidia の 次世代 RTX 4080 に関する発表を心待ちにしています。