")
ChatGPT は すぐに生成 AI の最愛の人になりましたが、ゲームの唯一のプレイヤーというわけではありません。画像生成など を行う他のすべての AI ツール に加えて、ChatGPT と直接競合するツールも多数あります。私はそう思っていました。
それについてChatGPTに聞いてみてはいかがでしょうか?それはまさに私がこのリストを取得するために行ったことであり、 「定員に達しました」という通知に直面している 人や、単に何か新しいことを試したい人のためのいくつかの選択肢を見つけることを望んでいます。これらのすべてが ChatGPT ほど一般にアクセスできるわけではありませんが、ChatGPT によれば、これらは最良の代替手段です。
Microsoft の Bing

AI によってリストされた選択肢に入る前に、ChatGPT に代わる最良の選択肢は、ChatGPT です。 Microsoft は最近 、この AI を自社の Bing 検索エンジンに追加し 、間もなくこの機能を Edge ブラウザに展開する予定です。
これはプレビュー段階にすぎませんが、 bing.com/new で今すぐ新しい AI チャットボットを試すことができます。 Microsoftは、当初はクエリの数を制限していると述べているが、 Bing ChatGPTの待機リストに参加する と、完全版が利用可能になったときに通知を受け取ることができる。
Google の BERT
BERT (Bidirectional Encoder Representations from Transformers) は、Google によって開発された機械学習モデルです。 ChatGPT の結果の多くは、このリストの後半で説明する Google によるプロジェクトについて言及しています。
BERT は、質問応答や感情分析などの自然言語処理 (NLP) 機能で知られています。 BookCorpus と英語版 Wikipedia を事前トレーニング参照のモデルとして使用しており、それぞれ 8 億語と 25 億語を学習しています。
BERT は、2018 年 10 月に オープンソースの研究プロジェクト および 学術論文 として初めて発表されました。その後、このテクノロジーは Google 検索に実装されました。 BERT に関する 初期の文献 では、2018 年 11 月にそれを OpenAI の ChatGPT と比較し、Google のテクノロジーが高度な双方向性を備えており、受信テキストの予測に役立つと指摘しています。一方、OpenAI GPT は一方向であり、複雑なクエリにのみ応答できます。
ミーナ by Google
Meena は、 Google が 2020 年 1 月に導入した 人間らしい会話機能を備えたチャットボットです。その機能の例には、ミーナが牛にハーバード大学で「牛の科学」を勉強するよう勧めるなど、興味深いジョークやダジャレを含む簡単な会話が含まれます。

OpenAI の GPT-2 の直接の代替品として、Meena は当時の競合他社の 8.5 倍のデータを処理する能力を持っていました。そのニューラル ネットワークは 2.6 個のパラメータで構成され、パブリック ドメインのソーシャル メディアでの会話でトレーニングされています。 Meena はまた、Sensibleness and Specificity Average (SSA) の指標スコアも 79% を獲得しており、当時最もインテリジェントなチャットボットの 1 つとなりました。
Meena コードは GitHub で入手できます。
ロベルタ by Facebook
RoBERTa (Robustly Optimized BERT Pretraining Approach) は、 Facebook が 2019 年 7 月に発表した オリジナルの BERT のもう 1 つの高度なバージョンです。
事前トレーニング モデルとして大規模なデータ ソースを使用して、この NLP モデルを作成しました。 RoBERTa は、2016 年 9 月から 2019 年 2 月までに生成された 6,300 万件の英語ニュース記事を 76 GB のデータセットとして含む CommonCrawl (CC-News) を使用しています。 Facebookによると、これと比較して、オリジナルのBERTは英語版WikipediaとBookCorpusのデータセット間で16GBのデータを使用しているという。
Facebook の調査によると、XLNet と同様に、RoBERTa は一連のベンチマーク データ セットで BERT を上回りました。これらの結果を得るために、同社はより大規模なデータ ソースを使用しただけでなく、モデルを 長期間にわたって事前 トレーニングしました。
Facebook は 2019 年 9 月に RoBERTa を オープンソースに し、そのコードはコミュニティの実験用に GitHub で入手できます 。
VentureBeat は、 当時新たに登場した AI システムの 1 つとして GPT-2 についても言及しました。
Google の XLNet
XLNET は 、Google Brain とカーネギー メロン大学の研究者 チームによって開発された、トランスフォーマー ベースの自己回帰言語モデルです。このモデルは本質的により高度な BERT であり、2019 年 6 月に初めて発表されました。グループは、XLNet が 2018 年に発表されたオリジナルの BERT よりも少なくとも 16% 効率的で あることを発見し、20 のテストで BERT を上回ることができました。 NLP タスク。
XLNet と BERT の両方が「マスクされた」トークンを使用して隠しテキストを予測するため、XLNet はプロセスの予測部分を高速化することで効率を向上させます。たとえば、Amazon Alexa データサイエンティストの Aishwarya Srinivasan 氏は、XLNet は、「York」という用語もその用語に関連付けられていると 予測 する前に、「New」という単語が「is a city」という用語に関連付けられているものとして識別できると説明しました。一方、BERT は、「New」と「York」という単語を個別に識別し、それらを、たとえば「都市である」という用語に関連付ける必要があります。
特に、2019 年のこの説明では、自己回帰言語モデルの他の例として GPT と GPT-2 も言及されて います。
XLNet コードと事前トレーニングされたモデルは GitHub で入手できます 。このモデルは NLP 研究コミュニティの間ではよく知られています。
Microsoft Research による DialoGPT
DialoGPT (Dialogue Generative Pre-trained Transformer) は、Microsoft Research によって 2019 年 11 月に 導入された 自己回帰言語モデルです。 GPT-2 との類似点により、このモデルは人間のような会話を生成するように事前トレーニングされています。ただし、主な情報源は Reddit のスレッドから収集された 1 億 4,700 万のマルチターン対話です。

HumanFirst のチーフ エバンジェリストである Cobus Greyling 氏は、DialoGPT を Telegram メッセージング サービスに実装し、チャットボットとしてモデルを実現することに成功したと述べています 。同氏は、Amazon Web Services と Amazon SageMaker を使用するとコードの微調整に役立つと付け加えました。
DialoGPT コードは GitHub で入手できます。
アルバート by Google
ALBERT (A Lite BERT) は、 オリジナルの BERT の短縮バージョンで、2019 年 12 月に Google によって開発されました。
ALBERT では、Google は「隠れ層埋め込み」を使用したパラメータを導入することで、モデル内で許可されるパラメータの数を制限しました。

これは、BERT モデルだけでなく、XLNet と RoBERTa でも改善されました。ALBERT は、より小さいパラメーターを遵守しながら、2 つの新しいモデルで使用されたのと同じ大規模な情報のデータセットでトレーニングできるためです。基本的に、ALBERT はその機能に必要なパラメーターのみを操作するため、パフォーマンスと精度が向上します。 Google は、SAT のような読解ベンチマークを含む 12 の NLP ベンチマークで ALBERT が BERT を上回っていることが判明したと詳細に説明しました。
名前は言及されていませんが、GPT は Google の Research ブログの ALBERT のイメージングに含まれています。
Google は 2020 年 1 月に ALBERT をオープンソースとしてリリースし、Google の TensorFlow 上に実装されました。コードは GitHub で入手できます。
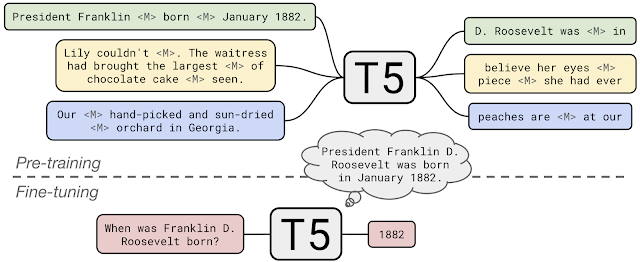
T5 by Google
SalesforceによるCTRL
GoogleのGShard
GShard は、 Google がニューラル ネットワークのスケーリングを目的として 2020 年 6 月に導入した 巨大な言語翻訳モデル です。モデルには 6,000 億個のパラメーターが含まれており、一度に大規模なデータ セットをトレーニングできます。 GShard は 言語翻訳 に特に優れており、4 日間で 100 の言語を英語に翻訳できるように訓練を受けています。
Facebook AI Research によるブレンダー
Blender は、Facebook AI Research によって 2020 年 4 月 に導入されたオープンソースのチャットボットです。このチャットボットは、競合他社のモデルに比べて会話スキルが向上しており、魅力的な話のポイントを提供し、パートナーの意見に耳を傾けて理解を示し、共感と個性を示す能力を備えていることが注目されています。
Blender は Google の Meena チャットボットと比較され、Meena チャットボットは OpenAI の GPT-2 と比較されます。
Blender コードは Parl.ai で入手できます。
Googleのペガサス
Pegasus は、2019 年 12 月に Google によって導入された 自然言語処理モデルです。Pegasus は、概要を作成するようにトレーニングでき、BERT、GPT-2、RoBERTa、XLNet、ALBERT、T5 などの他のモデルと同様に、問題なく作成できます。特定のタスクに合わせて調整されます。 Pegasus は、人間の被験者と比較して、ニュース、科学、記事、説明書、電子メール、特許、法案の要約における効率性がテストされています。

Pegasus コードは GitHub で入手できます。